什么是Hadoop?
Apache Hadoop是一个开放源代码软件框架,用于开发在分布式计算环境中执行的数据处理应用程序。
使用HADOOP构建的应用程序可在分布在商用计算机群集上的大型数据集上运行。商品计算机便宜且可广泛获得。这些主要用于以低成本实现更大的计算能力。
与驻留在个人计算机系统的本地文件系统中的数据类似,在Hadoop中,数据驻留在称为 Hadoop分布式文件系统的分布式文件系统中。处理模型基于 “数据局部性” 概念,其中计算逻辑被发送到包含数据的群集节点(服务器)。这种计算逻辑无非是用高级语言(例如Java)编写的程序的编译版本。这样的程序可以处理存储在Hadoop HDFS中的数据。
你知道吗?计算机集群由一组相互连接并充当单个系统的多个处理单元(存储磁盘+处理器)组成。
在本教程中,您将学习
一、Hadoop生态系统和组件
二、Hadoop架构
三、Hadoop的功能
四、Hadoop中的网络拓扑
一、Hadoop生态系统和组件
下图显示了Hadoop生态系统中的各个组件-
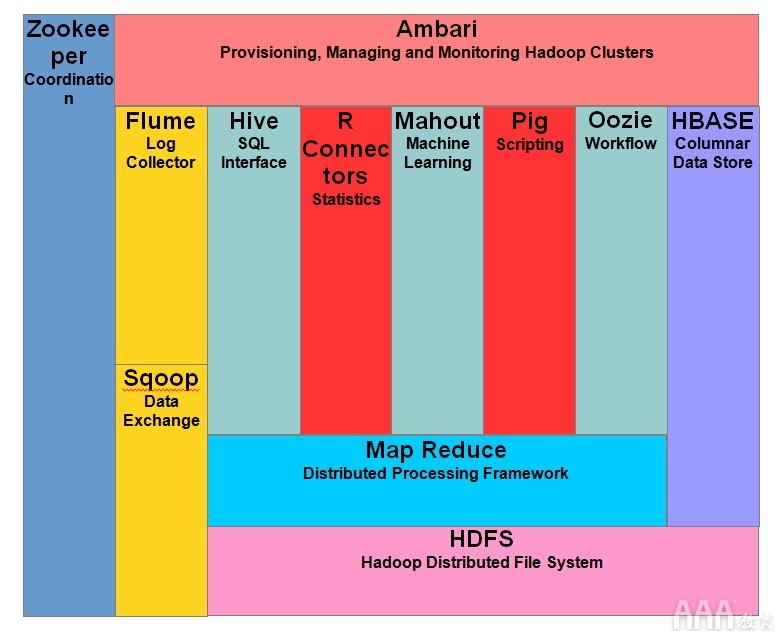
Apache Hadoop由两个子项目组成–
Hadoop MapReduce: MapReduce是用于编写在Hadoop上运行的应用程序的计算模型和软件框架。这些MapReduce程序能够在大型计算节点群集上并行处理大量数据。
HDFS (Hadoop分布式文件系统):HDFS负责Hadoop应用程序的存储部分。MapReduce应用程序使用HDFS中的数据。HDFS创建数据块的多个副本,并将它们分布在群集中的计算节点上。这种分布实现了可靠且快速的计算。
尽管Hadoop以MapReduce及其分布式文件系统HDFS而闻名,但该术语还用于一系列相关项目,这些项目属于分布式计算和大规模数据处理的范畴。Apache的其他与Hadoop相关的项目包括 Hive,HBase,Mahout,Sqoop,Flume和ZooKeeper。
二、Hadoop架构
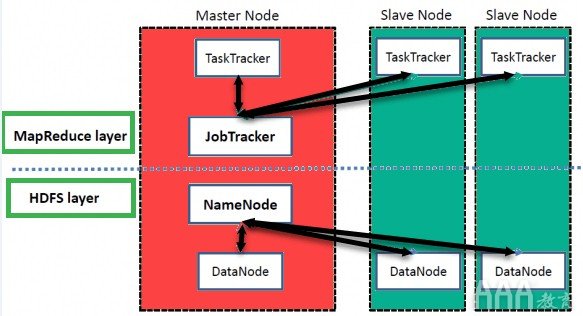
高级Hadoop架构
Hadoop具有使用MapReduce和HDFS方法进行数据存储和分布式数据处理的主从结构。
NameNode:
NameNode表示名称空间中使用的每个文件和目录
数据节点:
DataNode可帮助您管理HDFS节点的状态,并允许您与块进行交互
主节点:
主节点允许您使用Hadoop MapReduce进行数据并行处理。
从节点:
从节点是Hadoop集群中的其他计算机,可让您存储数据以进行复杂的计算。此外,所有从属节点都随附有Task Tracker和一个DataNode。这使您可以分别与NameNode和Job Tracker同步进程。
在Hadoop中,可以在云或本地中设置主系统或从系统
三、Hadoop的功能
•适用于大数据分析
由于大数据实际上倾向于分布和非结构化,因此HADOOP群集最适合分析大数据。由于流向计算节点的是处理逻辑(不是实际数据),因此消耗的网络带宽更少。该概念称为 数据局部性概念 ,它有助于提高基于Hadoop的应用程序的效率。
•可扩展性
通过添加其他群集节点,可以轻松地将HADOOP群集扩展到任何程度,从而实现大数据的增长。同样,扩展不需要修改应用程序逻辑。
容错
HADOOP生态系统提供了将输入数据复制到其他群集节点的规定。这样,在群集节点发生故障的情况下,仍然可以通过使用存储在另一个群集节点上的数据来进行数据处理。
四、Hadoop中的网络拓扑
当Hadoop群集的大小增长时,网络的拓扑(安排)会影响Hadoop群集的性能。除了性能之外,还需要关注高可用性和故障处理。为了实现此Hadoop,集群形成利用了网络拓扑。

通常,网络带宽是组成任何网络时要考虑的重要因素。但是,由于测量带宽可能很困难,因此在Hadoop中,网络被表示为一棵树,并且该树的节点之间的距离(跳数)被视为Hadoop集群形成的重要因素。在此,两个节点之间的距离等于它们到其最接近的共同祖先的距离之和。
Hadoop集群由一个数据中心,机架和实际执行作业的节点组成。在这里,数据中心由机架组成,而机架由节点组成。进程可用的网络带宽取决于进程的位置。也就是说,随着我们远离-
1、在同一节点上处理;
2、同一机架上的不同节点;
3、同一数据中心不同机架上的节点;
4、不同数据中心中的节点。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






