在这个由物联网(IoT),社交媒体,边缘计算以及越来越多的计算能力(如量子计算)支持的数字时代,数据可能是任何企业最有价值的资产之一。正确(或不正确)的数据管理将对企业的成功产生巨大影响。换句话说,它可以成败一个企业。
这就是原因,为了利用这些巨大的数据,无论大小,企业都在使用机器学习和深度学习等技术,以便他们可以建立有用的客户群,增加销售量并提高品牌忠诚度。
但是在大多数情况下,由于具有许多收集源和各种格式(结构化和非结构化),数据可能是不准确,不一致和冗余的。
通过向机器学习算法提供具有此类异常的数据,我们是否可以及时,全面地访问相关信息?
不,当然不!首先需要清除此类数据。
这就是数据清理的地方!
数据清理是建立有效的机器学习模型的第一步,也是最重要的一步。至关重要!
简而言之,如果尚未清理和预处理数据,则机器学习模型将无法正常工作。
尽管我们经常认为数据科学家将大部分时间都花在修补ML算法和模型上,但实际情况有所不同。大多数数据科学家花费大约80%的时间来清理数据。
为什么?由于ML中的一个简单事实,
换句话说,如果您具有正确清理的数据集,则简单的算法甚至可以从数据中获得令人印象深刻的见解。
我们将在本文中涉及与数据清理相关的一些重要问题:
a.什么是数据清理?
b.为什么需要它?
c.数据清理有哪些常见步骤?
d.与数据清理相关的挑战是什么?
e.哪些公司提供数据清理服务?
让我们一起开始旅程,了解数据清理!
数据清洗到底是什么?
数据清理,也称为数据清理,用于检测和纠正(或删除)记录集,表或数据库中的不准确或损坏的记录。广义上讲,数据清除或清除是指识别不正确,不完整,不相关,不准确或其他有问题(“脏”)的数据部分,然后替换,修改或删除该脏数据。
通过有效的数据清理,所有数据集都应该没有任何在分析期间可能出现问题的错误。
为什么需要数据清理?
通常认为数据清理是无聊的部分。但这是一个有价值的过程,可以帮助企业节省时间并提高效率。
这有点像准备长假。我们可能不喜欢准备部分,但我们可以提前收紧细节,以免遭受这一噩梦的困扰。
我们只需要这样做,否则我们就无法开始玩乐。就这么简单!
让我们来看一些由于“脏”数据而可能在各个领域出现的问题的示例:
a.假设广告系列使用的是低质量的数据并以不相关的报价吸引用户,则该公司不仅会降低客户满意度,而且会错失大量销售机会。
b.如果销售代表由于没有准确的数据而未能联系潜在客户,则可以了解对销售的影响。
c.任何规模大小的在线企业都可能因不符合其客户的数据隐私规定而受到政府的严厉处罚。例如,Facebook因剑桥数据分析违规向联邦贸易委员会支付了50亿美元的罚款。
d.向生产机器提供低质量的操作数据可能会给制造公司带来重大问题。
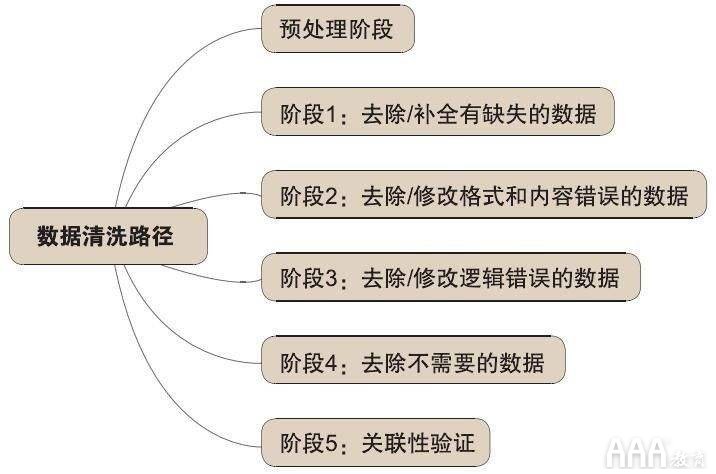
数据清理涉及哪些常见步骤?
每个人都进行数据清理,但没人真正谈论它。当然,这不是机器学习的“最奇妙”部分,是的,没有任何隐藏的技巧和秘密可以发现。
尽管不同类型的数据将需要不同类型的清除,但是我们在此处列出的常见步骤始终可以作为一个良好的起点。
因此,让我们清理数据中的混乱!
删除不必要的观察
数据清理的第一步是从我们的数据集中删除不需要的观测值。不需要的观察包括重复或不相关的观察。
a.在数据收集过程中,最常见的是重复或多余的观察结果。例如,当我们组合多个地方的数据集或从客户端接收数据时,就会发生这种情况。随着数据的重复,这种观察会在很大程度上改变效率,并且可能会增加正确或不正确的一面,从而产生不忠实的结果。
b.不相关的观察结果实际上与我们要解决的特定问题不符。例如,在手写数字识别领域,扫描错误(例如污迹或非数字字符)是无关紧要的观察结果。这样的观察结果是任何没有用的数据,可以直接删除。
修复结构错误
数据清理的下一步是修复数据集中的结构错误。
结构错误是指在测量,数据传输或其他类似情况下出现的那些错误。这些错误通常包括:
a.功能名称中的印刷错误(typos),
b.具有不同名称的相同属性,
c.贴错标签的类,即应该完全相同的单独的类,
d.大小写不一致。
例如,模型应将错字和大小写不一致(例如“印度”和“印度”)视为同一个类别,而不是两个不同的类别。与标签错误的类有关的一个示例是“不适用”和“不适用”。如果它们显示为两个单独的类,则应将它们组合在一起。
这些结构错误使我们的模型效率低下,并给出质量较差的结果。
过滤不需要的离群值
数据清理的下一步是从数据集中过滤掉不需要的离群值。数据集包含离训练数据其余部分相距甚远的异常值。这样的异常值会给某些类型的ML模型带来更多问题。例如,线性回归ML模型的稳定性不如Random Forest ML模型强。
但是,离群值在被证明有罪之前是无辜的,因此,我们应该有一个合理的理由删除一个离群值。有时,消除异常值可以提高模型性能,有时却不能。
我们还可以使用离群值检测估计器,这些估计器总是尝试拟合训练数据最集中的区域,而忽略异常观察值。
处理丢失的数据
机器学习中看似棘手的问题之一是“缺少数据”。为了清楚起见,您不能简单地忽略数据集中的缺失值。出于非常实际的原因,您必须以某种方式处理丢失的数据,因为大多数应用的ML算法都不接受带有丢失值的数据集。
让我们看一下两种最常用的处理丢失数据的方法。
a.删除具有缺失值的观察值:
这是次优方式,因为当我们丢弃观察值时,也会丢弃信息。原因是,缺失的值可能会提供参考,在现实世界中,即使某些功能缺失,我们也经常需要对新数据进行预测。
b.根据过去或其他观察结果估算缺失值:
这也是次优的方法,因为无论我们的估算方法多么复杂,原始值都会丢失,这总是会导致信息丢失。由于缺少值可能会提供信息,因此应该告诉我们的算法是否缺少值。而且,如果我们推算我们的价值观,我们只是在加强其他功能已经提供的模式。
简而言之,关键是告诉我们的算法最初是否缺少值。
那么我们该怎么做呢?
a.要处理分类特征的缺失数据,只需将其标记为“缺失”即可。通过这样做,我们实质上是添加了新的功能类别。
b.要处理丢失的数字数据,请标记并填充值。通过这样做,我们实质上允许算法估计缺失的最佳常数,而不仅仅是用均值填充。
与数据清理相关的主要挑战是什么?
尽管数据清理对于任何组织的持续成功都是必不可少的,但它也面临着自己的挑战。一些主要挑战包括:
a.对引起异常的原因了解有限。
b.错误地删除数据会导致数据不完整,无法准确地“填写”。
c.为了帮助提前完成该过程,构建数据清理图非常困难。
d.对于任何正在进行的维护,数据清理过程既昂贵又费时。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






