如果您曾经想通过流数据或快速变化的数据在线学习Python,那么您可能会熟悉数据管道的概念。数据管道允许您通过一系列步骤将数据从一种表示形式转换为另一种表示形式。数据管道是数据工程的关键部分,我们将在新的“ 数据工程师之路”中进行讲授。在本教程中,我们将逐步使用Python和SQL建立数据管道。
数据管道的一个常见用例是找出有关您网站访问者的信息。如果您熟悉Google Analytics(分析),那么您就会知道查看访问者的实时和历史信息的价值。在此博客文章中,我们将使用Web服务器日志中的数据来回答有关访问者的问题。
如果您不熟悉,则每次访问网页(例如Dataquest Blog)时,都会从Web服务器向浏览器发送数据。要托管此博客,我们使用一个称为Nginx的高性能Web服务器。输入网址并查看结果的过程如下:
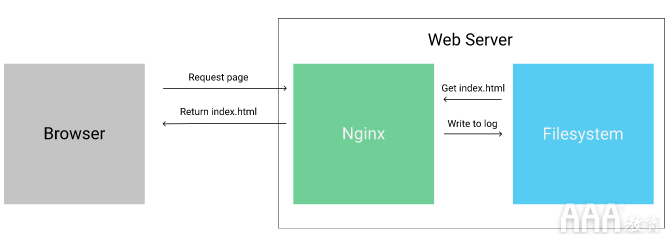
从Web浏览器向服务器发送请求的过程。
首先,客户端向Web服务器发送请求以请求某个页面。然后,Web服务器从文件系统加载页面并将其返回给客户端(Web服务器也可以动态生成页面,但是我们现在不必担心这种情况)。Web服务器在处理请求时,在文件系统上的日志文件中写入一行,其中包含有关客户端和请求的一些元数据。该日志使某人可以稍后查看谁在什么时间访问了网站上的哪些页面,并执行其他分析。
以下是此博客的Nginx日志中的几行:
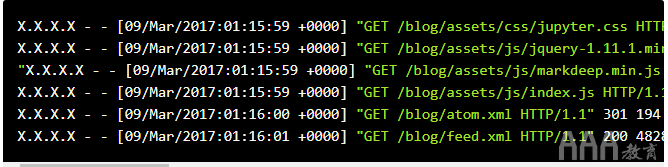
每个请求都是一行,随着对服务器的请求,行按时间顺序追加。每行的格式是Nginx combined格式,内部看起来像这样:

请注意,日志格式使用的变量,例如$remote_addr,之后将被特定请求的正确值替换。以下是日志格式的每个变量的说明:
a.$remote_addr—向服务器发出请求的客户端的IP地址。对于日志的第一行,这是X.X.X.X(出于隐私目的,我们删除了ips)。
b.$remote_user—如果客户端通过基本身份验证进行了身份验证,则为用户名。在第一条日志行中为空白。
c.$time_local—发出请求的当地时间。09/Mar/2017:01:15:59 +0000在第一行。
d.$request— 请求的类型,以及发出请求的URL。GET /blog/assets/css/jupyter.css HTTP/1.1在第一行。
e.$status— 来自服务器的响应状态代码。200在第一行。
f.$body_bytes_sent—服务器在响应正文中发送给客户端的字节数。30294在第一行。
g.$http_referrer—在发送当前请求之前客户端所在的页面。https://www.dataquest.io/blog/在第一行。
h.$http_user_agent—有关客户端的浏览器和系统的信息。Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/53.0.2785.143 Chrome/53.0.2785.143 Safari/537.36 PingdomPageSpeed/1.0 (pingbot/2.0; +http://www.pingdom.com/)在第一行。
随着对它的更多请求,Web服务器不断向日志文件添加行。有时,Web服务器会旋转过大的日志文件,并存档旧数据。
可以想象,公司通过了解哪些访客在他们的网站上以及他们在做什么而获得了很多价值。例如,意识到使用Google Chrome浏览器的用户很少访问某个页面,可能表明该页面在该浏览器中存在渲染问题。
另一个例子是知道每天有多少国家的用户访问您的网站。它可以帮助您确定将市场营销重点放在哪些国家。在最简单的层面上,仅了解您每天有多少访问者就可以帮助您了解营销工作是否正常进行。
为了计算这些指标,我们需要解析日志文件并进行分析。为此,我们需要构建一个数据管道。
关于数据管道的思考
这是一个数据管道的简单示例,该数据管道计算每天有多少访问者访问该站点:

每天从原始日志获取访问者计数。
正如您在上面看到的,我们从原始日志数据转到仪表板,在该仪表板中我们可以查看每天的访客数。请注意,该管道连续运行-将新条目添加到服务器日志时,它将捕获它们并进行处理。关于我们如何构建管道,您希望已经注意到一些事情:
a.每个管道组件都彼此分开,并接受定义的输入,并返回定义的输出。
b.尽管此处未显示,但可以将这些输出缓存或保留以进行进一步分析。
c.我们将原始日志数据存储到数据库中。这样可以确保,如果我们要进行其他分析,则可以访问所有原始数据。
d.我们删除重复的记录。在分析过程中引入重复数据非常容易,因此在通过管道传递数据之前进行重复数据删除至关重要。
e.每个管道组件将数据馈送到另一个组件。我们希望使每个组件尽可能小,以便我们可以分别按比例放大管道组件,或将输出用于不同类型的分析。
现在,我们已经了解了该管道的高层情况,让我们在Python中实现它。
处理和存储Web服务器日志
为了创建数据管道,我们需要访问Web服务器日志数据。我们创建了一个脚本,该脚本将连续生成伪造(但有些现实)的日志数据。这是如何遵循这篇文章:
a.克隆此仓库。
b.请按照自述文件安装Python要求。
c.运行python log_generator.py。
运行脚本后,您应该看到新条目被写入log_a.txt同一文件夹中。100写入行后log_a.txt,脚本将旋转到log_b.txt。它将保持每100行在文件之间来回切换。
启动脚本后,我们只需要编写一些代码来提取(或读入)日志。该脚本将需要:
a.打开日志文件并逐行读取它们。
b.将每一行解析为字段。
c.将每一行和已解析的字段写入数据库。
d.确保没有将重复的行写入数据库。
如果要继续,此 代码位于此存储库的store_logs.py文件中。
为了实现我们的第一个目标,我们可以打开文件并继续尝试从文件中读取行。
以下代码将:
a.在读取模式下打开两个日志文件。
b.永远循环。
c.找出两个文件当前正在读取的字符在哪里(使用tell方法)。
d.尝试从两个文件中读取一行(使用readline方法)。
e.如果两个文件均未写入任何行,请稍睡片刻,然后重试。
f.在睡觉之前,将读取点设置回我们原来的位置(在调用之前readline),以使我们不会错过任何事情(使用seek方法)。
g.如果其中一个文件写入了一行,请抓住该行。回想一下一次只能写入一个文件,因此我们无法从两个文件中获取行。
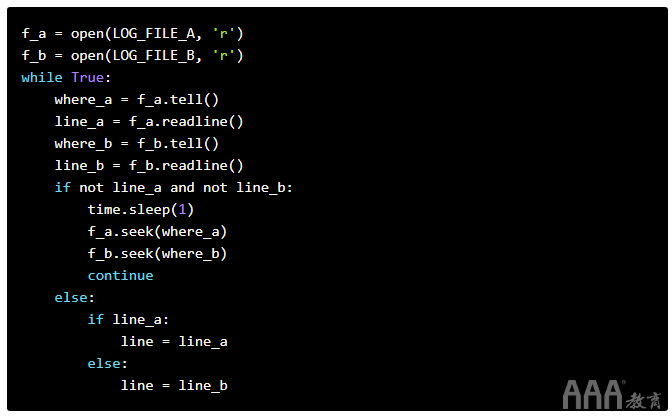
读完日志文件后,我们需要进行一些非常基本的解析,以将其拆分为多个字段。我们不想在这里做任何花哨的事情-我们可以将其保存下来,以供以后的步骤使用。通常,您希望管道中的第一步(保存原始数据的第一步)尽可能轻巧,因此发生故障的机会很小。如果此步骤在任何时候都失败了,您将最终丢失一些原始数据,这些原始数据将无法恢复!
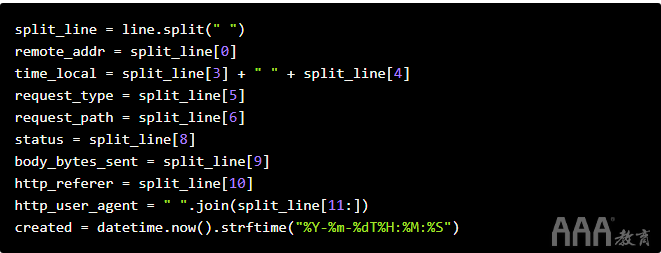
为了使解析简单,我们将在空格()字符上进行拆分,然后进行一些重组:

将日志文件解析为结构化字段。
在下面的代码中,我们:
a.取一条日志行,并在空格字符()上进行分割。
b.从拆分表示中提取所有字段。
c.请注意,某些字段在这里看起来不是“完美”的-例如,时间仍会带有括号。
d.初始化一个created变量,该变量存储创建数据库记录的时间。这将使将来的管道步骤可以查询数据。
我们还需要为我们的SQLite数据库表确定一个架构,并运行所需的代码来创建它。因为我们希望此组件简单,所以最好使用简单的架构。我们将使用以下查询创建表:
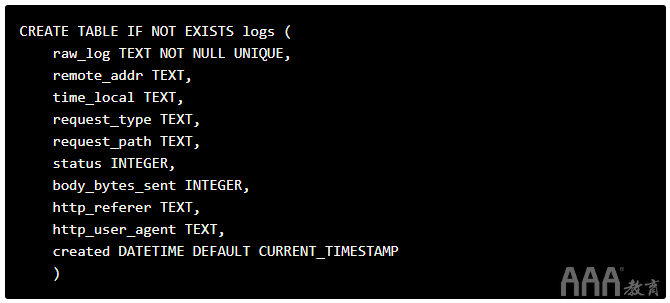
请注意我们如何确保每个记录raw_log都是唯一的,因此我们避免重复记录。另外,请注意我们如何将所有已解析的字段与原始日志一起插入数据库。有一个论点是我们不应该插入已解析的字段,因为我们可以轻松地再次计算它们。但是,将它们添加到字段中会使将来的查询变得更加容易(例如,我们可以仅选择time_local列),并且节省了下一行的计算工作量。
保留原始日志对我们很有帮助,以防万一我们需要一些我们未提取的信息,或者以后各行中字段的顺序变得很重要。由于这些原因,存储原始数据始终是一个好主意。
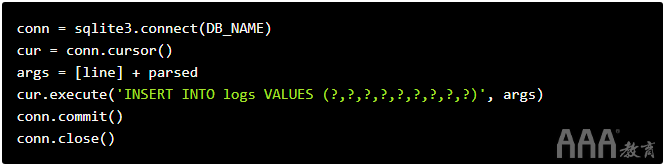
最后,我们需要将已解析的记录插入SQLite数据库的logs表中。选择一个数据库来存储此类数据非常关键。在这种情况下,我们选择SQLite是因为它很简单,并将所有数据存储在一个文件中。如果您更关心性能,那么使用Postgres这样的数据库可能会更好。
在下面的代码中,我们:
a.连接到SQLite数据库。
b.实例化游标以执行查询。
c.将所有我们将插入表中的值放在一起(parsed是我们之前解析的值的列表)
d.将值插入数据库。
e.提交事务,以便将其写入数据库。
f.关闭与数据库的连接。
我们刚刚完成了产品开发的第一步!现在,我们已经存储了重复数据删除的数据,接下来我们可以继续统计访问者了。
用数据管道统计访问者
我们可以使用几种不同的机制在流水线步骤之间共享数据:
a.档案
b.资料库
c.Queue列
在每种情况下,我们都需要一种从当前步骤到下一步获取数据的方法。如果将下一步(按天统计ip)指向数据库,则可以根据时间查询添加事件,从而提取事件。尽管通过使用队列将数据传递到下一步将获得更高的性能,但目前性能并不重要。
我们将创建另一个文件count_visitors.py,并添加一些将数据从数据库中拉出并按天进行计数的代码。
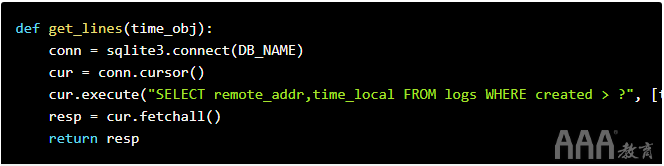
我们首先要从数据库查询数据。在下面的代码中,我们:
a.连接到数据库。
b.查询在某个时间戳记之后添加的任何行。
c.提取所有行。
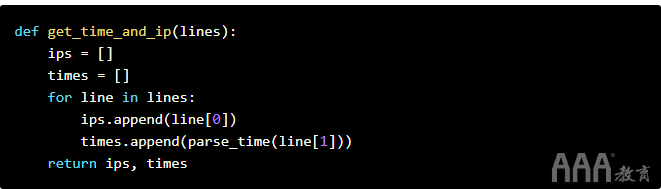
然后,我们需要一种从查询的每一行中提取IP和时间的方法。以下代码将:
a.初始化两个空列表。
b.从查询响应中提取时间和IP,并将其添加到列表中。
您可能会注意到,在上面的代码中,我们将时间从字符串解析为datetime对象。解析代码如下:

整理好片段后,我们只需要一种从数据库中提取新行并将其添加到每天访问量中的方法。以下代码将:
a.根据给定的开始时间从数据库中获取行以进行查询(我们将获取在给定时间之后创建的所有行)。
b.datetime从行中 提取IP和对象。
c.如果有任何行,请将开始时间指定为我们有一行的最晚时间。这样可以防止我们多次查询同一行。
d.创建一个密钥,day用于计算唯一IP。
e.将每个ip添加到每天仅包含唯一ip的集合中。
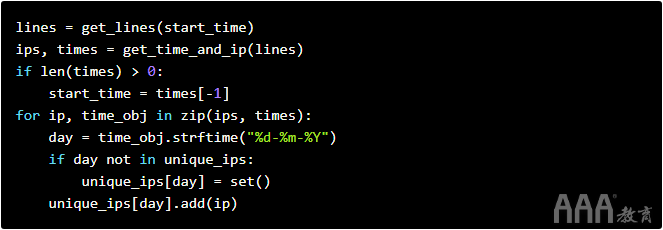
此代码将确保unique_ips每天都有一个密钥,并且值将是一组设置,其中包含当天到达该站点的所有唯一ip。
每天对ip进行分类后,我们只需要进行一些计数即可。在下面的代码中,我们:
a.将每天的访问者数量分配给counts。
b.从中提取元组列表counts。
c.对列表进行排序,以便按顺序排列日期。
d.打印出每天的访客计数。
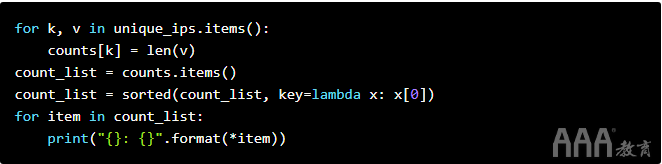
然后,我们可以从上方获取代码段,以便它们每秒钟运行一次5:
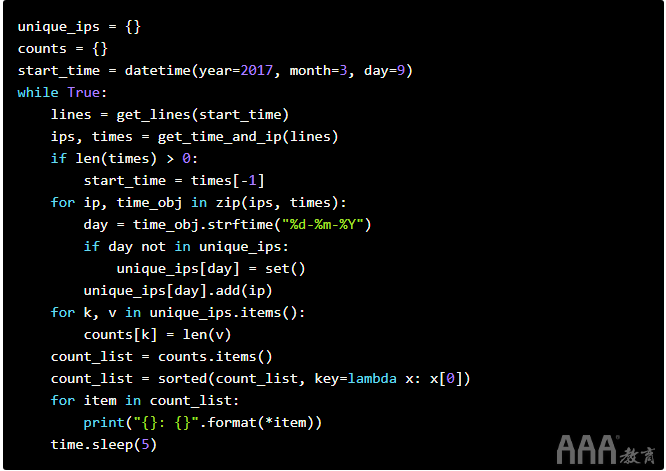
共同努力
现在,我们浏览了一个脚本以生成日志,并通过两个管道步骤来分析日志。为了使完整的管道运行:
a.如果还没有,请从Github 复制analytics_pipeline存储库。
b.按照README.md文件进行所有设置。
c.执行log_generator.py。
d.执行store_logs.py。
e.执行count_visitors.py。
运行后count_visitors.py,您应该看到每秒打印出当天的访客计数5。如果您将脚本运行几天,就会开始看到访客数天。
恭喜你!您已经设置并运行数据管道。现在让我们创建另一个从数据库中提取的管道步骤。
向数据管道添加另一个步骤
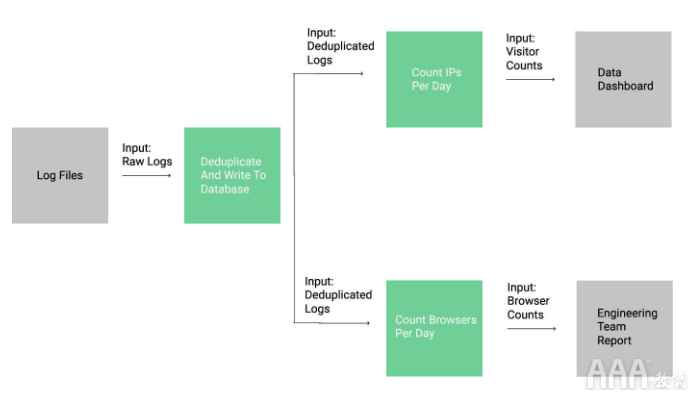
将管道分成多个部分的主要好处之一是,很容易将一步的输出用于另一目的。让我们试着算出访问每个网站的浏览者的人数,而不是计算访问者的人数。这将使我们的管道如下所示:
现在,我们有一个管道步骤驱动两个下游步骤。
如您所见,一步转换的数据可以是两个不同步的输入数据。如果要遵循此流水线步骤,则应查看count_browsers.py克隆的存储库中的文件。
为了对浏览器进行计数,我们的代码与计数访客的代码基本保持不变。主要区别在于我们解析用户代理以检索浏览器的名称。在下面的代码中,您会注意到我们查询的是http_user_agent列而不是remote_addr,并且我们解析了用户代理以找出访问者正在使用的浏览器:
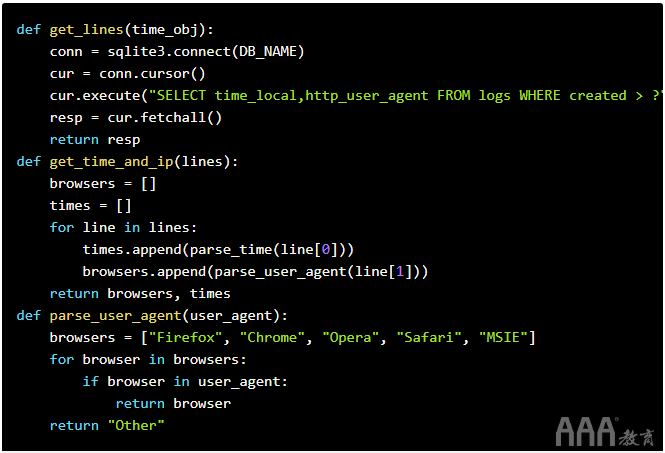
然后,我们修改循环以统计访问该网站的浏览器:
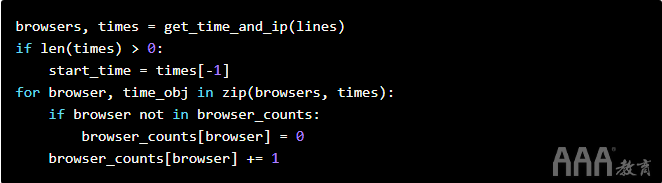
进行这些更改后,我们便python count_browsers.py可以计算出有多少浏览器正在访问我们的网站。
现在,我们已经创建了两个基本数据管道,并演示了数据管道的一些关键原理:
a.使每个步骤都很小。
b.使用定义的接口在管道之间传递数据。
c.存储所有原始数据以供以后分析。
扩展数据管道
在完成此数据管道教程之后,您应该了解如何使用Python创建基本数据管道。但是现在不要停止!随意扩展我们实施的管道。这里有一些想法:
a.您可以建立一个可以处理更多数据的管道吗?如果连续生成日志消息怎么办?
b.您可以对IP进行地理位置定位以找出访问者在哪里吗?
c.您能找出哪些网页最常被点击吗?
如果您有权访问真实的Web服务器日志数据,则可能还需要在该数据上尝试其中一些脚本,以查看是否可以计算出任何有趣的指标。
是否想通过交互式深入的数据工程课程将您的技能提升到一个新的水平?试试我们的数据工程师之路,它可以帮助您从头开始学习数据工程。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






