第一次学习SQL时,通常在单个表中处理数据。在现实世界中,数据库通常具有多个表中的数据。如果我们希望能够使用该数据,则必须在一个查询中合并多个表。在此SQL联接教程中,我们将学习如何使用联接从多个表中选择数据。
我们假设您了解使用SQL的基础知识,包括过滤,排序,聚合和子查询。如果您不这样做,我们的SQL基础课程将教授所有这些概念,您可以免费参加该课程。
概况资料库
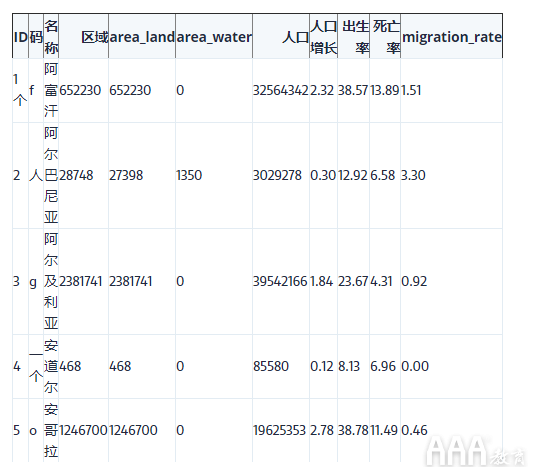
我们将使用具有两个表的CIA World Factbook(Factbook)数据库版本。第一个表格称为facts,每行代表Factbook中的国家/地区。这是facts表格的前5行:
除了该facts表外,还有第二个表cities,其中包含《概况》中各个国家/ 地区的主要城市区域的信息(在本教程的其余部分中,我们将使用“城市”一词来表示与“主要城市区域”相同的含义) 。让我们看一下该表的前几行,以及每列代表的描述:
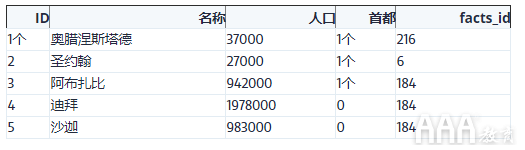
1)id –每个城市的唯一ID。
2)name –城市名称。
3)population –城市人口。
4)capital–城市是否为省会城市:1如果是,0如果不是。
5)facts_id– facts表中国家的ID 。
最后一列对我们特别有意义,因为它是原始facts表中也存在的一列数据。表之间的链接很重要,因为它用于合并查询中的数据。下面是一个架构图,它显示了数据库中的两个表,其中的列以及如何链接这两个表。
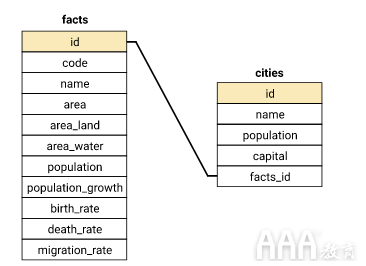
模式图中的线清楚地显示id了facts表中的facts_id列与cities表中的列之间的链接。
如果您想下载数据库以在自己的计算机上继续学习,则可以将数据集下载为SQLite数据库。
我们的第一个SQL连接
使用SQL连接数据的最常见方法是使用内部连接。内部联接的语法为:

内部连接子句由两部分组成:
1)INNER JOIN,它告诉SQL引擎您希望在查询中联接的表的名称,并希望使用内部联接。
2)ON,它告诉SQL引擎使用哪些列来连接两个表。
联接通常在FROM子句之后的查询中使用。让我们看一下一个基本的内部联接,在其中合并两个表中的数据。

让我们看一下其中包含联接的查询行:
1)INNER JOIN cities:这告诉SQL引擎我们希望cities使用内部联接将表联接到查询中。
2)ON cities.facts_id = facts.id:按照语法告诉SQL引擎在连接数据时使用哪些列table_name.column_name。
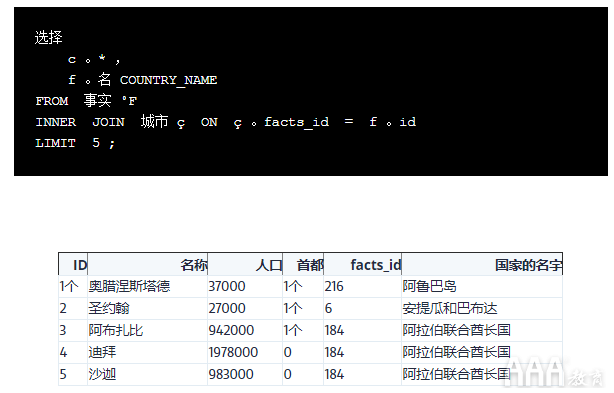
您可能会认为这SELECT * FROM facts将意味着查询仅返回表中的列facts,但是将*通配符与联接一起使用时,将为您提供两个表中的所有列。这是此查询的结果:
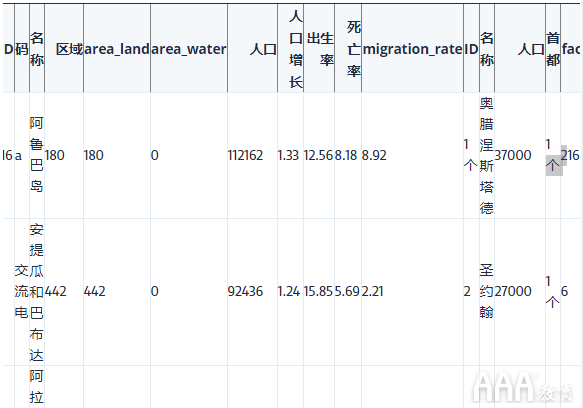
该查询为我们提供了两个表中的所有列,以及每行中idfrom facts和facts_idfrom 之间的匹配项cities(仅限于前5行)。
了解SQL内部联接
现在,我们已经将两个表合并在一起,以向我们提供有关中每行的更多信息cities。让我们仔细看看这个内部联接是如何工作的。
内部联接的工作方式是仅包含每个表中具有使用ON子句指定的匹配项的行。让我们看一下上一个屏幕中的联接如何工作的图。我们包含了一些行,这些行最能说明连接:
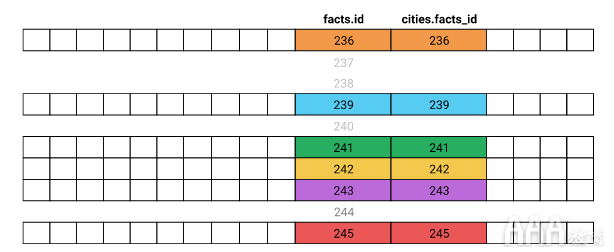
我们的内部联接将包括:
a.从行cities表中有cities.facts_id一个匹配facts.id的facts。
我们的内部联接将不包括:
a.从行cities表中有一个cities.facts_id不匹配任何facts.id从facts。
b.从行facts表中有一个facts.id不匹配任何cities.facts_id从cities。
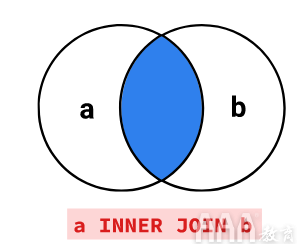
您可以看到这以维恩图表示:
我们已经知道如何使用别名为列指定自定义名称,例如:

我们还可以为表名创建别名,这使带有联接的查询更易于读写。代替:

我们可以这样写:

就像列名一样,using AS是可选的。通过写可以得到相同的结果:

我们还可以将别名与通配符结合使用-例如,使用上面创建的别名,c.*将为我们提供表中的所有列cities。
虽然我们在上一个屏幕中的查询包含了该ON子句中的两列,但ON在最终的列列表中,我们不需要使用该子句中的任何一列。这很有用,因为这意味着我们只能显示我们感兴趣的信息,而不必每次都包含两个联接列。
让我们使用我们学到的内容来构建原始查询。好:
a.加入cities到facts使用INNER JOIN。
b.使用别名作为表名。
c.按顺序包括:
1)来自的所有列cities。
2)name从facts别名到 的列country_name。
d.仅包括前5行。
在SQL中练习内部联接
让我们练习编写一个查询,以使用内部联接来回答数据库中的问题。假设我们要使用到目前为止所学的知识,从数据库中生成国家及其首都城市的表格。我们的第一步是考虑在最终查询中需要哪些列。我们需要:
1)name来自 的专栏facts
2)name来自 的专栏cities
鉴于我们已经确定需要两个表中的数据,因此需要考虑如何将它们联接。前面的模式图表明,每个表中只有一列将它们链接在一起,因此我们可以对这些列使用内部联接来联接数据。
到目前为止,考虑到我们的问题,我们已经可以编写大部分查询了(与我们之前编写的查询几乎相同):
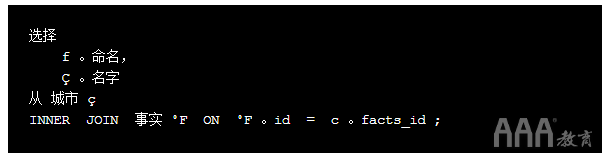
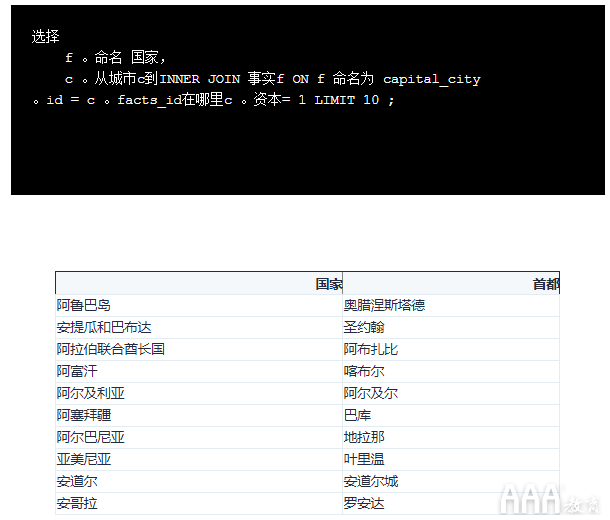
我们过程的最后一部分是确保我们具有正确的行。从前面的两个屏幕,我们知道,像这样的查询将返回所有行cities中具有相应匹配从facts在facts_id列。我们只对“城市”表中的首都感兴趣,因此我们需要WHERE在该capital列上使用一个子句,该子句的值是1城市是否为首都,是否为首都0:

现在,我们可以将所有这些放在一起编写一个查询,以回答我们的问题。我们将其限制为仅前10行,以便可以管理输出量。
SQL中的左联接
如前所述,内部联接将不包括两个表中没有相互匹配的行。这意味着可能存在我们在查询中看不到的信息,其中行不匹配。
我们可以使用SQL查询来探索这一点:
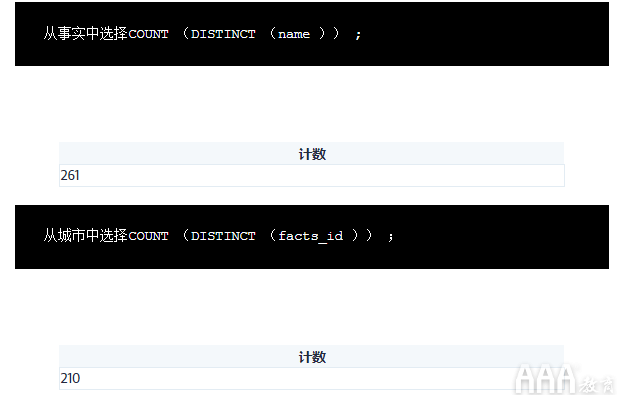
通过运行这两个查询,我们可以看到facts表中有些国家的表中没有对应的城市cities,这表明我们可能有一些不完整的数据。
让我们看一下如何创建查询以使用新型连接(左连接)来探索丢失的数据。
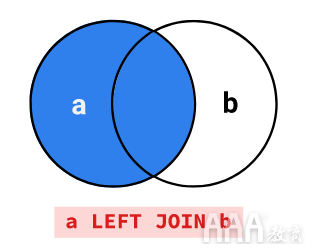
左联接包括内部联接将选择的所有行,以及第一(或左)表中与第二表不匹配的任何行。我们可以看到这以维恩图表示。
让我们看一个示例,方法INNER JOIN是LEFT JOIN从我们编写的第一个查询中替换为,并与之前的图中的行进行相同的选择
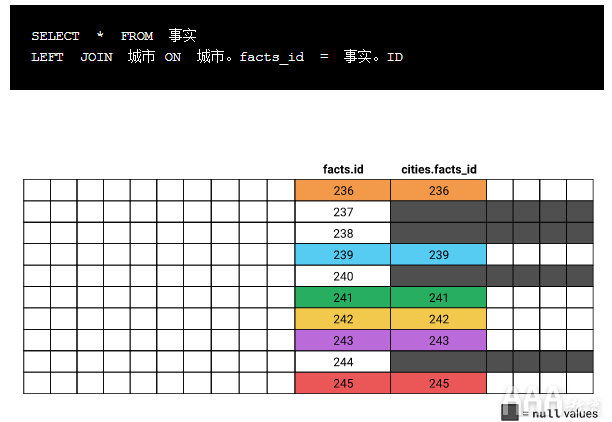
在这里我们可以看到,对于与(237、238、240和244)facts.id中的任何值都不匹配cities.facts_id的行,结果中仍包含这些行。发生这种情况时,cities表中的所有列都将填充空值。
我们可以使用这些空值将结果过滤到仅cities包含WHERE子句的国家/地区。在SQL中与null进行比较时,我们使用IS关键字而不是=符号。如果要选择列为空的行,可以编写:

如果要选择列名不为空的行,请使用:

让我们使用左联接来探索cities表中不存在的国家。
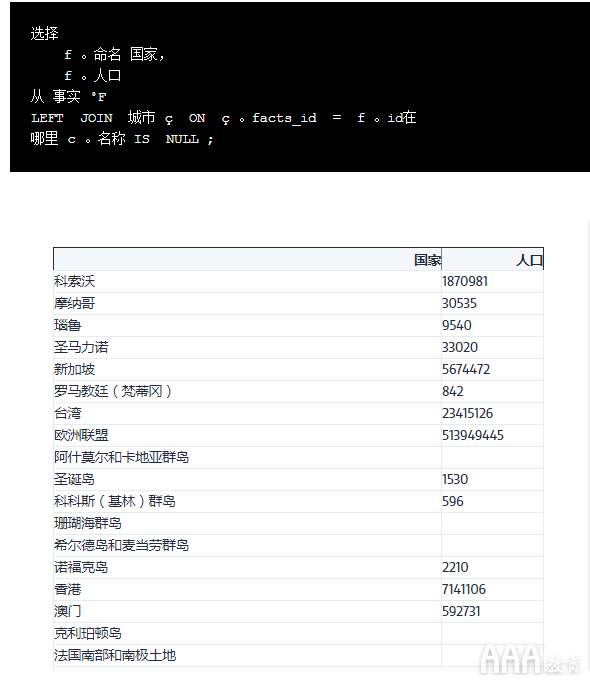
通过查看我们在上一个屏幕中编写的查询结果,我们可以看到许多不同的原因,导致国家在以下方面没有相应的值cities:
a.人口少和/或没有主要城市地区(定义为人口超过750,000)的国家,例如圣马力诺,科索沃和瑙鲁。
b.摩纳哥和新加坡等城市州。
c.本身不是国家的领土,例如香港,直布罗陀和库克群岛。
d.不是国家/地区的地区和海洋,例如欧盟和太平洋。
e.真实的数据丢失案例,例如台湾。
每当您使用内部联接时要谨记自己可能会排除重要数据,这一点很重要,尤其是如果要基于数据库模式中未链接的列进行联接时,这一点很重要。
右连接和外连接
SQLite不支持两种不常见的联接类型,您应该注意这些联接类型。首先是正确的联接。顾名思义,右连接与左连接完全相反。左联接包括该子句之前JOIN表中的所有行,而右联接包括该JOIN子句中新表中的所有行。我们可以在下面的维恩图中看到一个右连接:
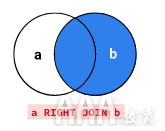
以下两个查询,一个使用左联接,一个使用右联接,产生相同的结果。

使用正确联接的主要原因是当您联接两个以上的表时。在这些情况下,最好使用右连接,因为它可以避免重组整个查询以连接一个表。除此之外,右联接很少使用,因此对于简单联接,使用左联接比右联接更好,因为其他人更容易阅读和理解您的查询。
SQLite不支持的另一种联接类型是完全外部联接。完整的外部联接将包括联接两侧表中的所有行。我们可以在下面的维恩图中看到完整的外部联接:
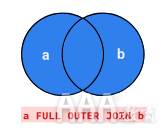
像右连接一样,完全外连接通常是不常见的。完全外部联接的标准SQL语法为:

当进行联接cities并facts使用完全外部联接时,结果将与上面的左右联接相同,因为中没有cities.facts_id不存在的值facts.id。
让我们并排查看每种联接类型的维恩图,这应该可以帮助您比较到目前为止我们已经讨论过的四种联接中每种联接的区别。
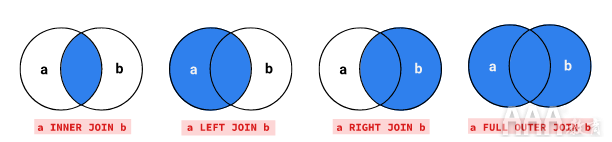
接下来,让我们练习使用联接来回答有关数据的一些问题。
寻找人口最多的首都城市
以前,我们在为查询结果指定顺序时使用了列名,如下所示:
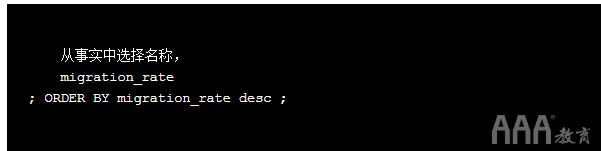
我们可以在查询中使用一个方便的快捷方式,使我们可以跳过列名,而使用列在SELECT子句中的显示顺序。在这种情况下,migration_rate是SELECT子句中的第二列,因此我们可以使用2而不是列名:

您可以在ORDER BYor GROUP BY子句中使用此快捷方式。请记住,您要确保查询仍然可读,因此对于更复杂的查询,键入完整的列名可能会更好。
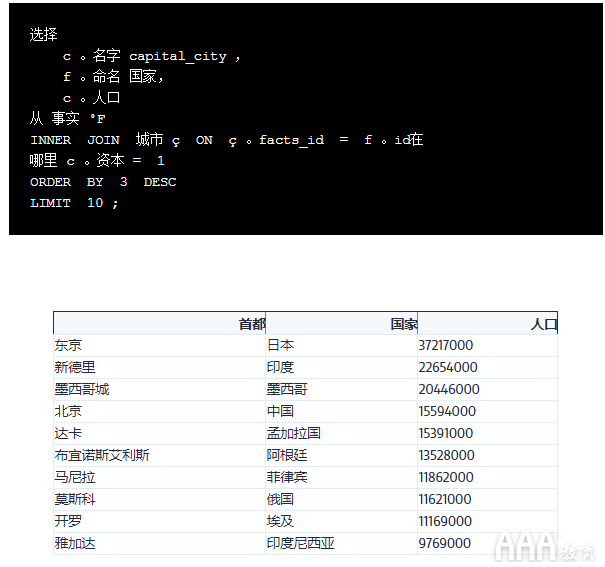
让我们利用我们所学的知识,按人口列出前十大首都城市的清单。由于我们对facts没有相应城市的国家不感兴趣cities,因此应使用INNER JOIN。
将SQL连接与子查询结合
子查询可用于替代部分查询,使我们能够找到更复杂问题的答案。我们也可以连接到子查询的结果,就像可以创建表一样。
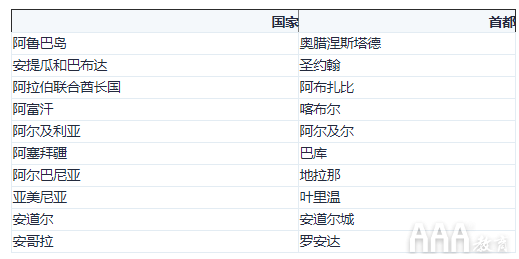
这是一个使用联接和子查询来生成国家及其首都城市表的示例,就像我们在任务早期所做的那样。

最初,读取子查询可能会让人不知所措,因此,我们将分几个步骤来分解本示例中发生的情况。要记住的重要一点是,任何子查询的结果总是首先计算得出,因此我们从内而外读取。
a.首先计算红色框中的子查询。这个简单的查询从中选择所有列cities,通过将值设置capital为1 来过滤标记为省会城市的行。
b.在INNER JOIN加入子查询结果,如别名c,在facts基于表ON的条款。
c.从联接结果中选择两列:
1)f.name,别名为country。
2)c.name,别名为capital_city。
d.结果仅限于前10行。
以下是此查询的输出:
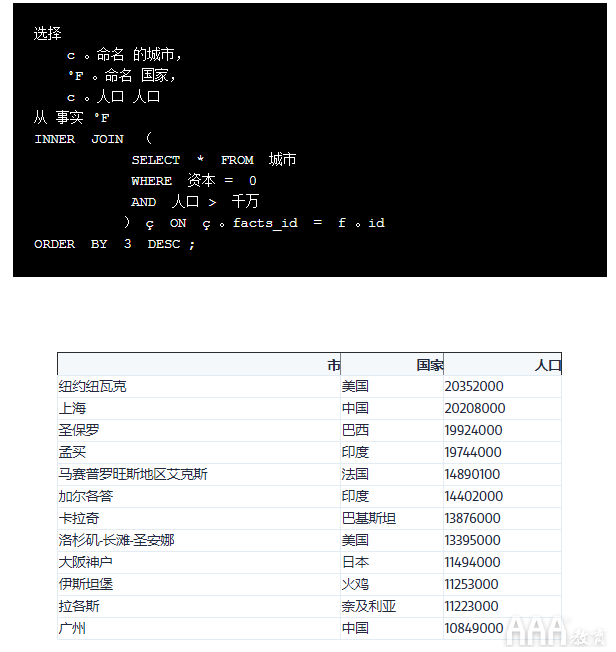
使用此示例作为模型,我们将编写一个类似的查询来查找人口超过1000万的非首都城市。
SQL挑战:具有联接和子查询的复杂查询
让我们把以前学过的所有东西都用起来,并用它来编写更复杂的查询。发现“ SQL思维”需要一点时间来适应并不少见,因此,如果一开始看起来很难理解该查询,不要气our。通过实践,它将变得更加容易!
当您使用联接和子查询编写复杂的查询时,遵循以下过程将有所帮助:
a.考虑一下最终输出中需要哪些数据
b.确定您需要联接哪些表,以及是否需要联接到子查询。
1)如果需要加入子查询,请首先编写子查询。
c.然后开始编写您的SELECT子句,然后是join和您需要的任何其他子句。
d.不要害怕逐步地编写查询,随心所欲地运行它,例如,在编写外部查询之前,可以先将子查询作为“独立”查询运行,以确保它看起来像您想要的。
我们将写一个查询来查找城市中心(城市)人口占该国总人口一半以上的国家。编写此查询的方法有多种,但我们将逐步介绍一种方法。
我们可以从编写查询开始,以汇总每个国家/地区城市的所有城市人口。我们可以通过不分组的方式做到这一点facts_id(在下面的示例中将使用限制以使输出可管理):
接下来,我们将facts表格连接到该子查询,选择国家/地区名称,城市人口和总人口(同样,我们使用限制来保持整洁):

最后,我们将创建一个新列,该列将城市人口除以总人口,并使用WHERE和ORDER BY过滤/排序结果:
您可以看到,虽然我们的最终查询很复杂,但是如果逐步构建它,则更容易理解。
SQL联接教程:后续步骤
在此sql join教程中,我们了解到:
a.内部联接和左联接之间的区别。
b.正确和外部连接的作用
c.如何选择适合您任务的联接。
d.对子查询,聚合函数和其他SQL技术使用联接。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






