在如何使用Python脚本转换数据和命令行中,我们将深入探讨如何使用Python脚本和命令行来转换数据。
但是首先,值得提出一个您可能正在思考的问题:“ Python如何适合命令行,为什么当我知道我可以使用IPython笔记本完成所有数据科学工作时,为什么还要使用命令行与Python进行交互?还是Jupyter实验室?”
笔记本非常适合快速进行数据可视化和探索,但是Python脚本是将我们学到的东西投入生产的一种方式。假设您想建立一个网站,以帮助人们发布具有理想标题和提交时间的Hacker News帖子。为此,您需要脚本。
本教程假定您具有函数的基本知识,并且有一点命令行经验也不会受到损害。如果您以前从未使用过Python,请随时查看我们涵盖Python函数基础的任务,或者更深入地研究我们的一些数据科学课程。最近,我们发布了两个新的交互式命令行课程:“ 命令行元素”和“命令行中的文本处理”,因此如果您想更深入地研究命令行,我们也建议您
也就是说,不必过分担心先决条件!我们将解释我们正在做的所有事情,所以让我们开始吧!
熟悉数据
Hacker News是一个站点,用户可以在该站点上通过Internet(通常是有关技术和创业公司)提交文章,而其他人可以“赞扬”这些文章,表示他们喜欢它们。提交的投票越多,在社区中就越受欢迎。热门文章进入Hacker News的“首页”,在其他网站上它们更有可能被他人看到。
我们将使用的数据集是由Arnaud Drizard使用Hacker News API编译的,可以在此处找到。我们从数据中随机抽取了10000行,并删除了所有多余的列。我们的数据集只有四列:
submission_time -故事提交时。
upvotes -提交的投票数。
url —提交的基本域。
headline—提交的标题。用户可以对其进行编辑,而不必与原始文章的标题相匹配。
我们将编写脚本来回答三个关键问题:
哪些新闻最常出现在头条新闻中?
哪些域名最常提交给Hacker News?
大多数文章什么时候提交?
切记:在编程时,有多种方法可以处理任务。在本教程中,我们将逐步解决这些问题,但是肯定还有其他方法同样有效,因此请随时尝试并尝试提出自己的方法!
使用命令行和Python脚本读取数据
要加注星标,让我们Transforming_Data_with_Python在桌面上创建一个文件夹。要使用命令行创建文件夹,可以使用mkdir命令,后跟文件夹名称。例如,如果要创建一个名为的文件夹test,则可以导航到Desktop目录,然后键入mkdir test。
我们将稍后讨论为什么创建文件夹,但是现在,让我们使用cd命令导航到创建的文件夹。该cd命令允许我们使用命令行更改目录。
尽管有多种使用命令行创建文件的方法,但我们可以利用一种称为管道传输和重定向输出的技术来一次完成两件事:将输出从stdout(命令行生成的标准输出)重定向到文件中并创建一个新文件!换句话说,我们可以让它创建一个新文件并使它的输出成为该文件的内容,而不是让命令行仅打印其输出。
要做到这一点,我们可以使用>和>>,这取决于我们想用文件来完成。如果文件不存在,两者都会创建一个文件;但是,>将使用重定向的输出覆盖文件中已有的文本,同时>>将任何重定向的输出附加到文件中。
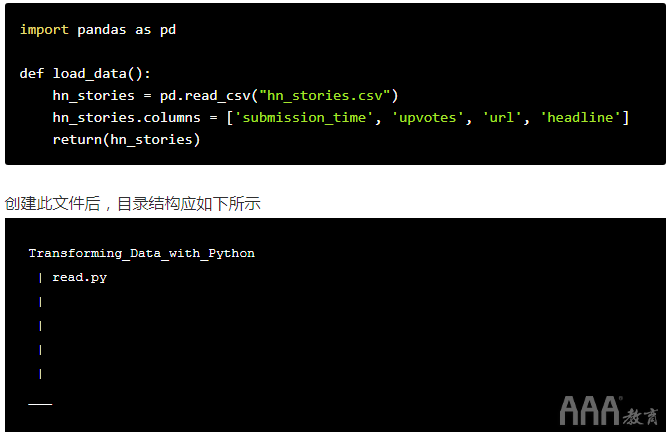
我们希望将数据读入该文件并创建一个描述性的文件名和函数名称,因此我们将创建一个名为的函数,load_data()并将其保存在名为的文件中read.py。让我们使用读取数据的命令行创建函数。为此,我们将使用该printf函数。(我们将使用printf它,因为它允许我们打印换行符和制表符,我们将使用它们来使脚本对自己和其他人更具可读性)。
为此,我们可以在命令行中输入以下内容
printf "import pandas as pd\n\ndef load_data():\n\thn_stories = pd.read_csv('hn_stories.csv')\n\thn_stories.colummns = ['submission_time', 'upvotes', 'url', 'headline']\n\treturn(hn_stores)\n" > read.py
检查上面的代码,有很多事情要做。让我们将其分解。在函数中,我们是:
a.请记住,我们要使脚本可读,我们正在使用printf命令通过命令行生成一些输出,以在生成输出时保留格式。
b.进口大熊猫。
c.将数据集(hn_stories.csv)读入pandas数据框。
d.使用df.columns列名添加到我们的数据帧。
e.创建一个名为的函数load_data(),其中包含用于读取和处理数据集的代码。
f.利用换行符(\n)和制表符(\t)保留格式,因此Python可以读取脚本。
g.将输出重定向printf到read.py使用>运算符调用的文件。由于read.py尚不存在,因此已创建文件。
运行上面的代码后,我们可以cat read.py在命令行中键入并执行命令以检查的内容read.py。如果一切正常运行,我们的read.py文件将如下所示:
创造 __init__.py
在该项目的其余部分,我们将创建更多脚本来回答我们的问题并使用该load_data()函数。尽管我们可以将该函数粘贴到使用该函数的每个文件中,但是如果我们正在处理的项目很大,则可能会变得非常麻烦。
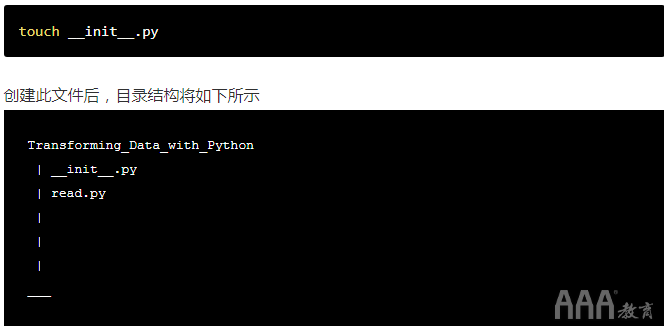
为了解决这个问题,我们可以创建一个名为的文件__init__.py。本质上,__init__.py允许文件夹将其目录文件视为包。最简单的形式__init__.py可以是一个空文件。它只需要存在就可以将目录文件视为包。您可以在Python文档中找到有关包和模块的更多信息。
因为load_data()是中的函数read.py,所以我们可以使用导入包的相同方法来导入该函数:from read import load_data()。
还记得使用命令行创建文件的多种方法吗?我们可以使用另一个命令来创建文件__init__.py这次,我们将使用该touch命令来创建文件。touch是一个在您运行命令后立即为您创建一个空文件的命令:
探索标题中的单词
现在,我们已经创建了一个脚本来读取和处理数据以及创建的数据__init__.py,我们可以开始分析数据了!我们要探索的第一件事是标题中出现的独特词。为此,我们要执行以下操作:
1)count.py使用命令行创建一个名为的文件。
2)load_data从导入read.py,并调用函数以读取数据集。
3)将所有标题合并为一个长长的字符串。当您合并标题时,我们希望在每个标题之间留一个空格。在此步骤中,我们将使用Series.str.cat连接字符串。
4)将长字符串拆分成单词。
5)使用Counter类可以计算每个单词在字符串中出现的次数。
6)使用该.most_common()方法将100个最常用的单词存储到wordCount。
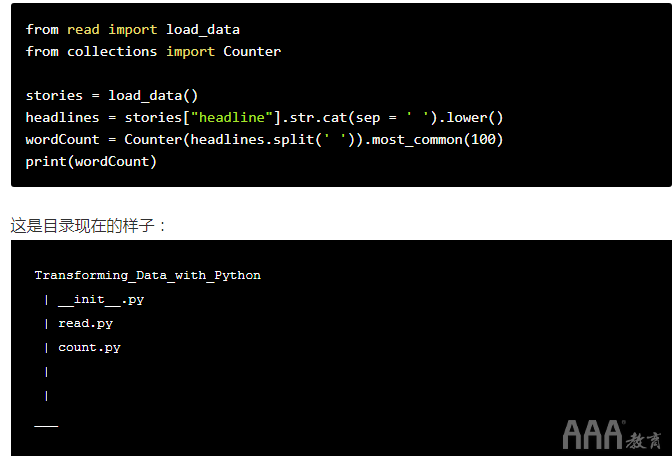
如果使用命令行创建此文件,则外观如下:
printf "from read import load_data\nfrom collections import Counter\n\nstories = load_data()\nheadlines = stories['headline'].str.cat(sep = ' ').lower()\nwordCount = Counter(headlines.split(' ')).most_common(100)\nprint(wordCount)\n" > count.py
运行上面的代码后,您可以cat count.py在命令行中键入并执行命令以检查的内容count.py。如果一切正常运行,您的count.py文件将如下所示:
现在,我们已经创建了Python脚本,我们可以从命令行运行脚本以获取一百个最常用单词的列表。要运行脚本,我们从命令行键入python count.py命令。
脚本运行后,您将看到以下打印结果:
[('the', 2045), ('to', 1641), ('a', 1276), ('of', 1170), ('for', 1140), ('in', 1036), ('and', 936), ('', 733), ('is', 620), ('on', 568), ('hn:', 537), ('with', 537), ('how', 526), ('-', 487), ('your', 480), ('you', 392), ('ask', 371), ('from', 310), ('new', 304), ('google', 303), ('why', 262), ('what', 258), ('an', 243), ('are', 223), ('by', 219), ('at', 213), ('show', 205), ('web', 192), ('it', 192), ('–', 184), ('do', 183), ('app', 178), ('i', 173), ('as', 161), ('not', 160), ('that', 160), ('data', 157), ('about', 154), ('be', 154), ('facebook', 150), ('startup', 147), ('my', 131), ('|', 127), ('using', 125), ('free', 125), ('online', 123), ('apple', 123), ('get', 122), ('can', 115), ('open', 114), ('will', 112), ('android', 110), ('this', 110), ('out', 109), ('we', 106), ('its', 102), ('now', 101), ('best', 101), ('up', 100), ('code', 98), ('have', 97), ('or', 96), ('one', 95), ('more', 93), ('first', 93), ('all', 93), ('software', 93), ('make', 92), ('iphone', 91), ('twitter', 91), ('should', 91), ('video', 90), ('social', 89), ('&', 88), ('internet', 88), ('us', 88), ('mobile', 88), ('use', 86), ('has', 84), ('just', 80), ('world', 79), ('design', 79), ('business', 79), ('5', 78), ('apps', 77), ('source', 77), ('cloud', 76), ('into', 76), ('api', 75), ('top', 74), ('tech', 73), ('javascript', 73), ('like', 72), ('programming', 72), ('windows', 72), ('when', 71), ('ios', 70), ('live', 69), ('future', 69), ('most', 68)]
在我们的网站上滚动浏览它们会有些尴尬,但是您可能会注意到最常见的词,例如等等。这些词被称为停用词the,to a for这些词对人类语音很有用,但对数据分析没有任何帮助。您可以在我们的spaCy教程中找到更多有关停用词的信息;如果要扩展此项目,则从我们的分析中删除停用词将是一个有趣的下一步。
即使包含了停用词,我们也可以发现一些趋势。除了停用词之外,这些词中的绝大多数都是与技术和创业相关的术语。考虑到HackerNews专注于科技创业公司,这并不奇怪,但是我们可以看到一些有趣的特定趋势。例如,谷歌是该数据集中最常提及的品牌。Facebook,Apple和Twitter等其他品牌也是讨论的热门话题。
探索域提交
现在我们已经探索了不同的标题并显示了前100个最常用的词,现在我们可以探索域提交了!为此,我们可以执行以下操作:
1)domains.py使用命令行创建一个名为的文件。
2)load_data从导入read.py,并调用函数以读取数据集。
3)使用value_counts()大熊猫中的方法来计算列中每个值的出现次数。
4)遍历该系列并打印索引值及其关联的总数。
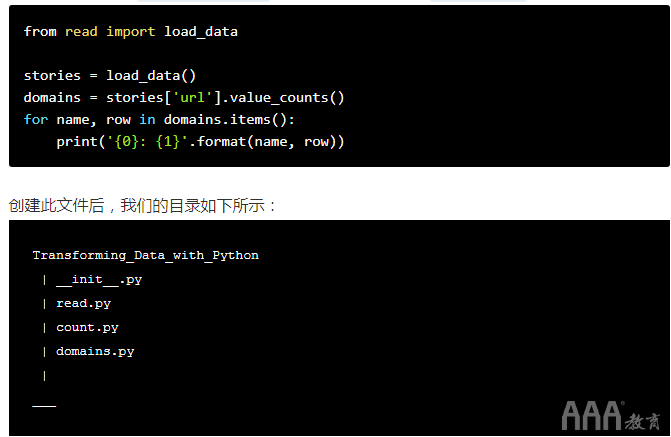
这是命令行形式的外观:
printf "from read import load_data\n\nstories = load_data()\ndomains = stories['url'].value_counts()\nfor name, row in domains.items():\n\tprint('{0}: {1}'.format(name, row))\n" > domains.py
再一次,如果我们cat domains.py在命令行中输入来检查domains.py,我们应该看到:
探索提交时间
我们想知道大多数文章何时提交。一种简单的重组方法是查看文章的提交时间。为了弄清楚这一点,我们需要使用该submission_time列。
该submission_time列包含如下时间戳:2011-11-09T21:56:22Z。这些时间以UTC表示,UTC是大多数软件用于保持一致性的通用时区(想象一个数据库中填充的时间都具有不同的时区;要使用它会非常麻烦)。
要从时间戳获取小时,我们可以使用该dateutil库。中的parser模块dateutil包含parse函数,该函数可以带一个时间戳,并返回一个datetime对象。这是文档的链接。解析时间戳后,hour结果日期对象的属性将告诉您文章提交的时间。
为此,我们可以执行以下操作:
1)times.py使用命令行创建一个名为的文件。
2)编写一个函数以从时间戳中提取小时。此函数应首先用于dateutil.parser.parse解析时间戳,然后从结果datetime对象中提取小时,然后使用来返回小时.hour。
3)使用pandas apply()方法创建提交时间列。
4)使用value_counts()大熊猫中的方法来计算每小时发生的次数。
5)打印结果。
我们在命令行中执行以下操作:
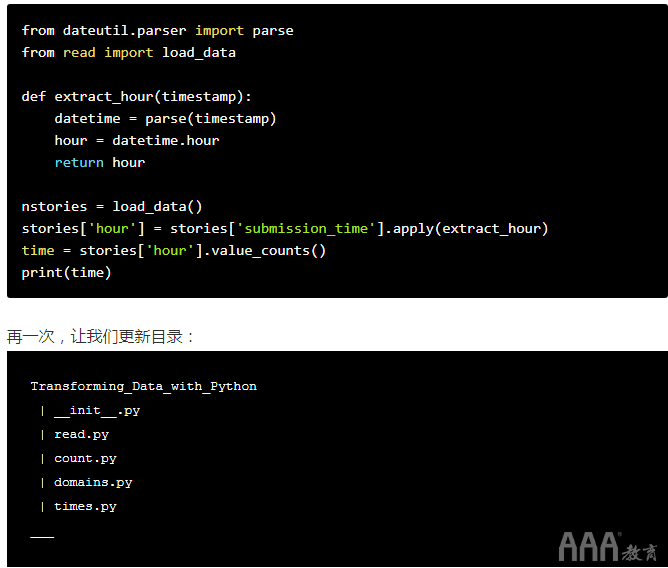
printf "from dateutil.parser import parse\nfrom read import load_data\n\n\ndef extract_hour(timestamp):\n\tdatetime = parse(timestamp)\n\thour = datetime.hour\n\treturn hour\n\nstories = load_data()\nstories['hour'] = stories['submission_time'].apply(extract_hour)\ntime = stories['hour'].value_counts()\nprint(time)" > times.py
这是它看起来像一个单独.py文件的样子(如上所述,您可以通过cat times.py从命令行运行以检查文件来进行确认):
现在,我们已经创建了Python脚本,我们可以从命令行运行脚本,以获取特定时间内发布了多少篇文章的列表。为此,您可以从命令行键入python times.py命令。运行此脚本,您将看到以下结果:
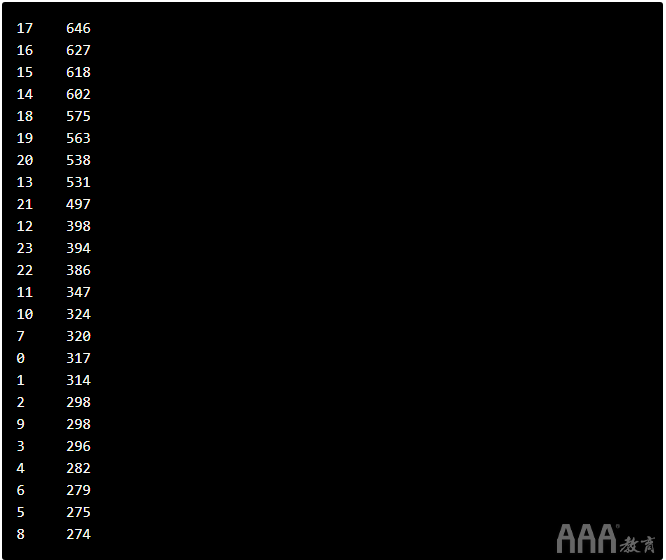
您会注意到大多数提交内容是在下午发布的。但是请记住,这些时间是UTC时间。如果您有兴趣扩展此项目,请尝试在脚本中添加一个部分,以将UTC的输出转换为本地时区。
下一步
在如何使用Python脚本转换数据和命令行中,我们探索了数据并建立了一个短脚本目录,这些短脚本可相互配合以提供所需的答案。这是构建我们的数据分析项目的生产版本的第一步。
但是,当然,这仅仅是开始!在如何使用Python脚本转换数据和命令行中,我们没有使用过upvotes数据,因此这是扩展分析范围的一个不错的下一步:
a.标题长度最大才能获得最多投票?
b.提交时间最多的是什么?
c.投票总数随时间变化如何?
我们鼓励您结合自己的问题,并在继续探索此数据集时发挥创造力!
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






