术语机器学习常常被错误互换与人工智能。实际上,机器学习是AI的一个子领域。机器学习有时也与预测分析或预测建模相混淆。同样,机器学习可用于预测建模,但这只是预测分析的一种类型,其用途比预测建模更广泛。
机器学习是计算机无需明确编程即可学习的能力
机器学习最基本的方法是使用编程算法来接收和分析输入数据,以预测可接受范围内的输出值。随着将新数据输入这些算法,他们将学习并优化其操作以提高性能,并随着时间的推移开发智能。
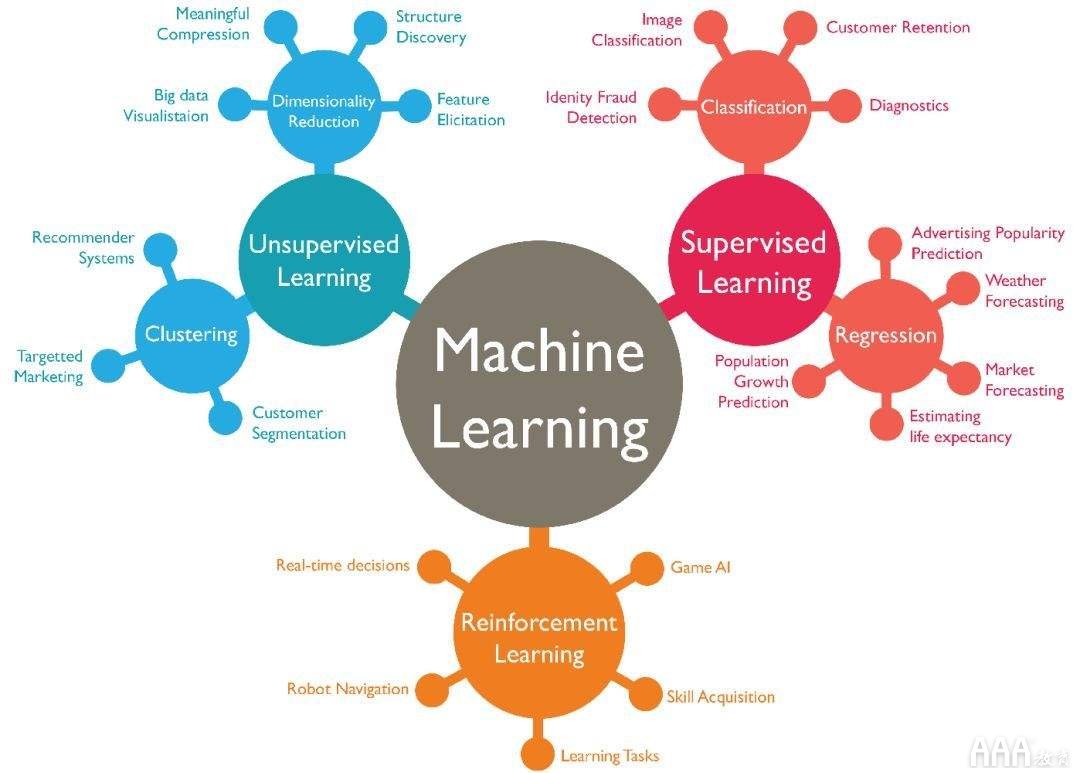
机器学习算法有四种类型:有监督,半监督,无监督和强化。
我应该使用哪种机器学习算法?
该备忘单可帮助你从各种机器学习算法中进行选择,以找到适合你特定问题的适当算法,并且整篇文章将引导你完成如何使用该表单的过程。
监督学习
在监督学习中,机器是通过示例进行教学的。操作员向机器学习算法提供一个包含所需输入和输出的已知数据集,并且该算法必须找到一种方法来确定如何得出这些输入和输出。当操作员知道问题的正确答案时,该算法可以识别数据中的模式,从观察中学习并做出预测。该算法进行预测并由操作员进行校正-直到该算法达到较高的准确性/性能水平为止,此过程将继续进行。
在监督学习的保护下,分类,回归和预测成为可能。
分类:在分类任务中,机器学习程序必须从观察值得出结论,并确定
新观察结果属于什么类别。例如,当将电子邮件过滤为垃圾邮件或非垃圾邮件时,程序将查看现有的观察数据并相应地过滤电子邮件。
回归:在回归任务中,机器学习程序必须估计并理解变量之间的关系。回归分析的重点是一个因变量和一系列其他变化变量,这使其对预测和预测特别有用。
预测:预测是根据过去和现在的数据对未来进行预测的过程,通常用于分析趋势。
监督学习与无监督学习,这两种流行的机器学习类型以及何时使用它们
差异真正归结为数据集中的观察结果代表你所了解的事物还是你要学习的关系的事物
半监督学习
半监督学习与监督学习相似,但是使用标签数据和未标签数据。标记数据本质上是具有有意义标签的信息,因此算法可以理解该数据,而未标记数据则缺少该信息。通过组合这些技术,机器学习算法可以学习标记未标记的数据。
无监督学习
在这里,机器学习算法研究数据以识别模式。没有答案键或人工操作员来提供说明。相反,机器通过分析可用数据来确定相关性和关系。在无监督的学习过程中,机器学习算法被用来解释大型数据集并相应地处理该数据。该算法尝试以某种方式组织数据以描述其结构。这可能意味着将数据分组到群集中或以看起来更有条理的方式进行排列。
当它评估更多数据时,其对该数据做出决策的能力逐渐提高并变得更加完善。
无监督学习技术包括:
聚类:聚类涉及将相似数据集(基于定义的标准)进行分组。将数据分成几组并对每个数据集进行分析以找到模式非常有用。
降维:降维减少了为了找到所需的确切信息而要考虑的变量数量。
强化学习
强化学习专注于有条理的学习过程,其中机器学习算法提供了一组动作,参数和最终值。通过定义规则,机器学习算法然后尝试探索不同的选项和可能性,监视和评估每个结果以确定哪个是最佳的。强化学习可以教机器尝试和错误。它从过去的经验中吸取教训,并开始根据情况调整其方法以实现最佳结果。
机器学习使用接收和分析输入数据的编程算法来预测可接受范围内的输出值。随着将新数据输入这些算法,他们将学习并优化其操作以提高性能,并随着时间的推移开发智能。
确定要使用的机器学习算法
选择正确的机器学习算法取决于几个因素,包括但不限于:数据大小,质量和多样性,以及企业希望从该数据中得出什么答案。其他注意事项包括准确性,训练时间,参数,数据点等等。因此,选择正确的算法是业务需求,规范,实验和可用时间的结合。
即使是经验最丰富的数据科学家,也无法在与其他人进行实验之前就告诉你哪种算法性能最好。但是,我们已经编写了一份机器学习算法备忘单,它将帮助你找到最适合自己的特定挑战。
最常见和最受欢迎的机器学习算法是什么?
在右侧的幻灯片中滚动以了解最常用的机器学习算法。该列表并非详尽无遗,但确实包含了数据科学家在解决业务问题时最有可能遇到的算法。
请记住,这些技术中有许多是组合在一起并一起使用的,通常你必须尝试不同的算法并比较结果来进行试验。
显然,在为你的业务分析选择正确的机器学习算法时,需要考虑很多因素。但是,你无需成为数据科学家或专业统计学家即可将这些模型用于你的业务。在AAA教育,我们的产品和解决方案利用全面的机器学习算法选择,帮助你开发可不断从数据中传递价值的流程。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






